



In short: MLFlow is far superior than Metaflow. So Learn MLFlow now.
-
 MLflow for Beginners199,00 €
MLflow for Beginners199,00 €
We compare two Machine Learning and Data Science frameworks – MLFlow vs. Metaflow. These Data Science and Machine Learning Frameworks are the most popular in their category – ML. They provide you a fixed set or best practices, methods, classed and helping tools (like UIs or APIs). They support your ML or DS Project Lifecycle.
If you want to learn more about Machine Learning, consider browsing through our Online Course Section!
Introduction MLFlow
MLFlow was developer and open sourced by Databricks. Here is how MetaFlow describes itself in their Intro Blog Post:
MLflow is designed to work with any ML library, algorithm, deployment tool or language. It’s built around REST APIs and simple data formats (e.g., a model can be viewed as a lambda function) that can be used from a variety of tools, instead of only providing a small set of built-in functionality. This also makes it easy to add MLflow to your existing ML code so you can benefit from it immediately, and to share code using any ML library that others in your organization can run.
Introduction Metaflow
The official Metaflow description of itself is very good, so here goes copy & paste:
Metaflow is a human-friendly Python library that helps scientists and engineers build and manage real-life data science projects. Metaflow was originally developed at Netflix to boost productivity of data scientists who work on a wide variety of projects from classical statistics to state-of-the-art deep learning.
Our framework provides a unified API to the infrastructure stack. It’s required to execute data science projects – from prototype to production.
Community, Popularity and Reliability
The popularity of framework is pretty important. Here is why. When you run into a problem, you will turn to Google and StackOverflow for help and you will beg that someone knows what framework you are using. So here is a Google Trends for MLFlow vs Metaflow. As you can see below, metaflow peaked shortly in late 2019. But overall, MLFlow wins.
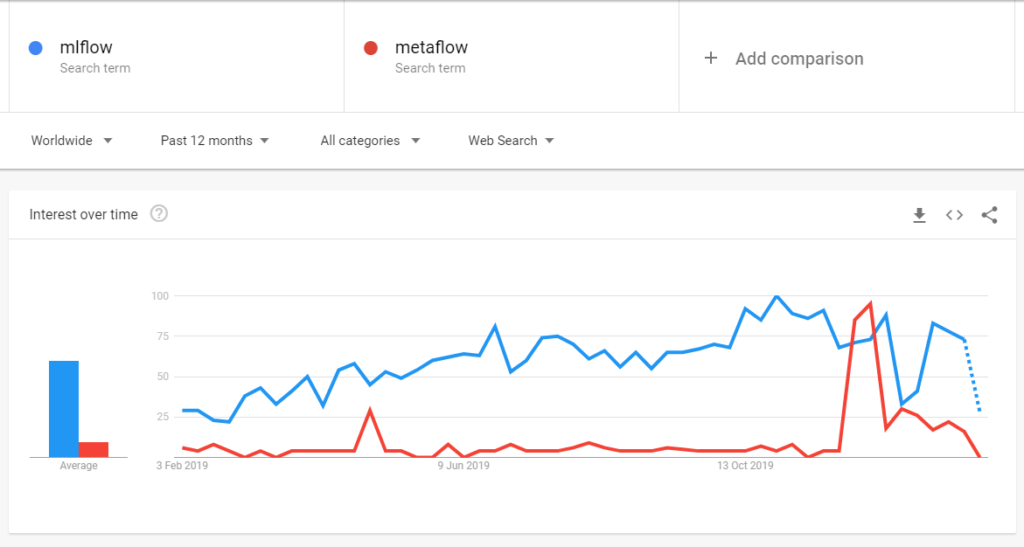
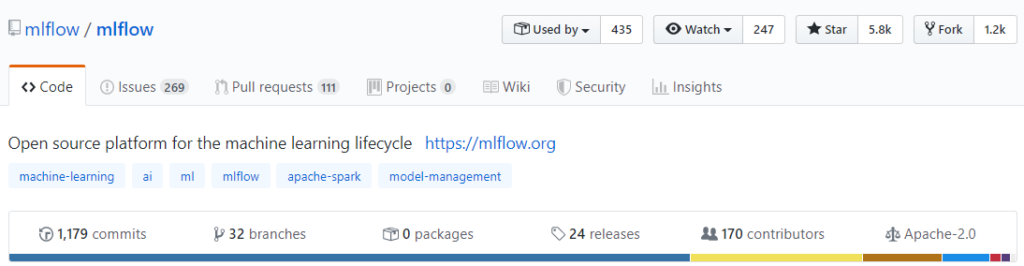
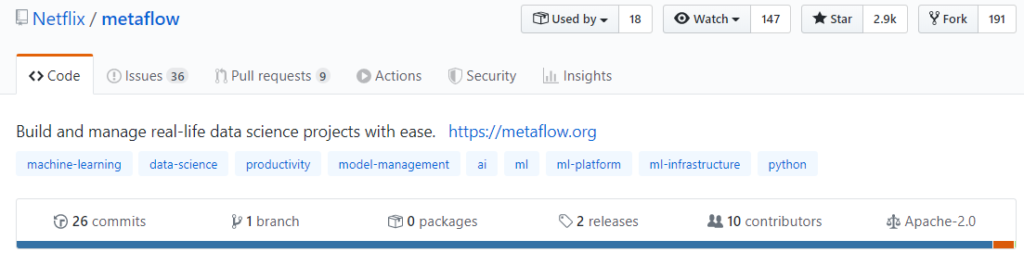
Another critical point is the Community behind a Codebase. The bigger the community the more reliable (in most cases) the codebase. The following Github Screenshots speak for themselves. And MLFLow wins again.
MLFlow
Metaflow
Meta-Logging, Training, Deploying
A ML Framework should provide us with a healthy balance between concrete ways to implement a new project – which reduces complexity. But it also should give us enough freedom to experiment and stay flexible for unusual business/technical environments.
The most pressing issue, in my experience, is the fact that when you train your model locally, you don’t save any data about this process. Re-producing the same results may be difficult. Or even a more simple task, just retrieve the training results from last week…you can’t, cause you started to tune your hyperparameters and retrained your model 10 times more that day. An ML framework should collect metadata about these and other similar processes.
MLFlow Tutorial
Let’s take a look at MLFlow from a practical side. Installation, Usage, UI, etc.
pip3 install mlflow
mlflow
Usage: mlflow [OPTIONS] COMMAND [ARGS]...
Options:
--version Show the version and exit.
--help Show this message and exit.
Commands:
artifacts Upload, list, and download artifacts from an MLflow artifact...
azureml Serve models on Azure ML.
db Commands for managing an MLflow tracking database.
experiments Manage experiments.
models Deploy MLflow models locally.
run Run an MLflow project from the given URI.
runs Manage runs.
sagemaker Serve models on SageMaker.
server Run the MLflow tracking server.
ui Launch the MLflow tracking UI for local viewing of run...
mlflow ui
Serving on http://localhost:5000Now let’s run the basic dummy script below to generate some meta/tracking data.
import mlflow
# Start an MLflow run
with mlflow.start_run():
# Log a parameter (key-value pair)
mlflow.log_param("param2", 3)
# Log a metric; metrics can be updated throughout the run
mlflow.log_metric("foo", 2, step=1)
mlflow.log_metric("foo", 4, step=2)
mlflow.log_metric("foo", 6, step=3)
# Log an artifact (output file)
with open("output.txt", "w") as f:
f.write("Hello world!")
mlflow.log_artifact("output.txt")python3 mlflow_test.py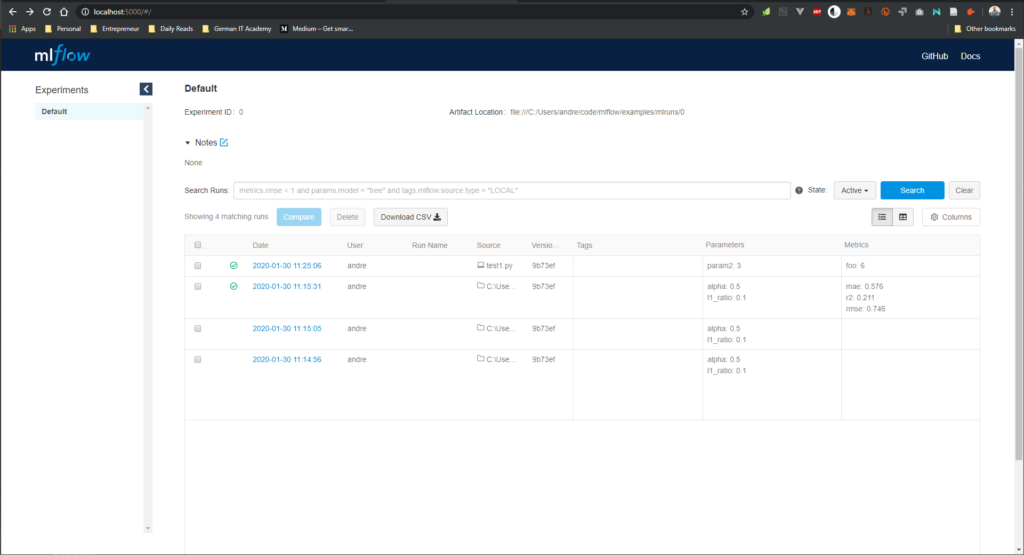
MLFlow UI Experiments
On the frontpage you can see all the executions that i executed either with „mlflow run …“ or with „python mlflow_code.py“.
You can see even those executions that failed. Which is pretty awesome for developing and debugging.
Extremely important is the feature of comparing different experiments with one another which you can do on this page.
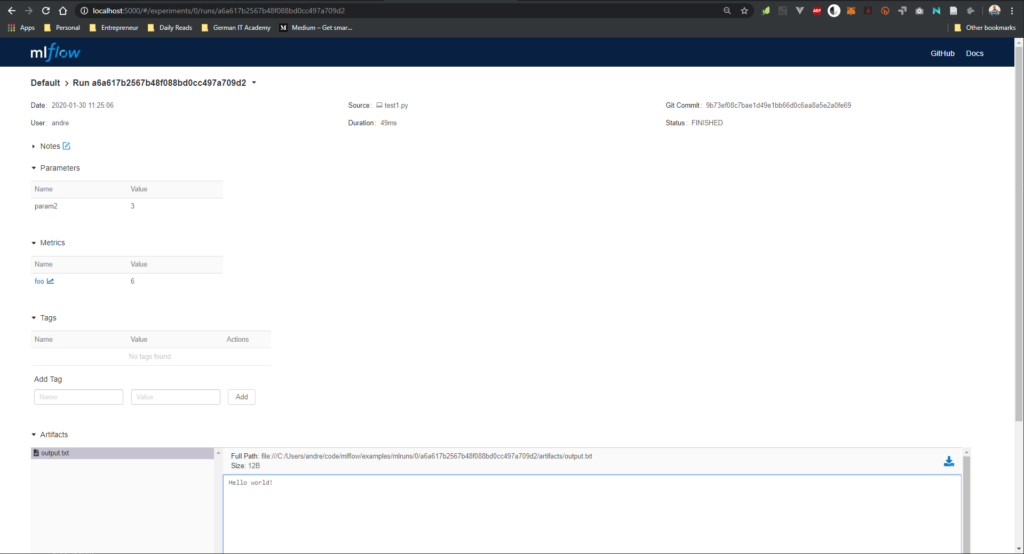
MLFlow UI Params
On the Single Experiment Page you’ll see stuff like Date, User, Source, Duration of this particular Experiment (Execution, Flow).
You also can see Tags and a List of Artifacts with Preview mode – which is awesome. In our case the dummy code from above generated a text file with „Hello World“ in it!
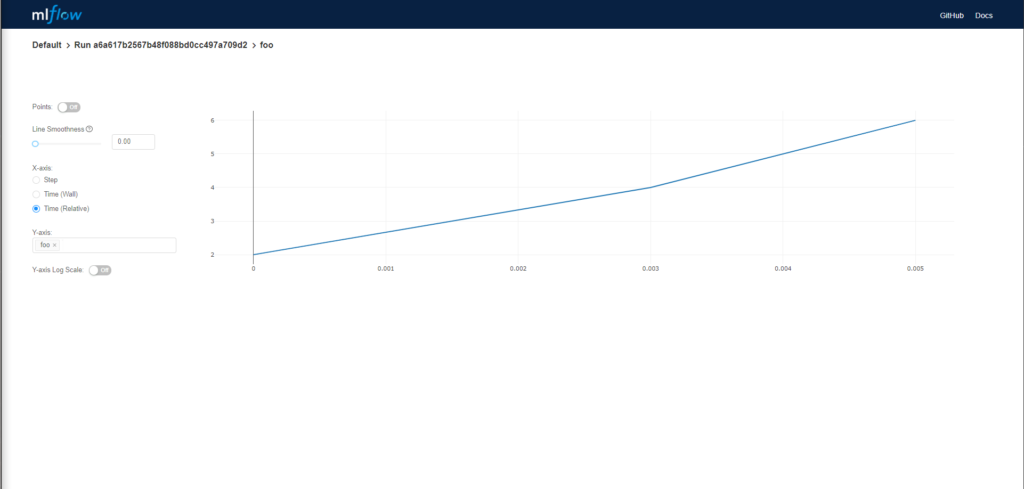
MLFlow UI Metric Chart
Another awesome feature of MLFLow is the chart which will display your metrics (that you set up manually) in a chart.
MetaFlow Tutorial
First of all, i’m on Windows. You can’t use MetaFlow on Windows without some crazy tweaks. In fact, MetaFlow said they won’t support Windows. So this is already is a nogo for me (shouldn’t be a problem if you are on Linux). For the purpose of demonstration i’ll boot a Linux EC2 Instance and play around there – obviously, you can’t develop effectively with EC2.
$ pip3 install metaflow==2.0.1
$ metaflow
Metaflow (2.0.1): More data science, less engineering
http://docs.metaflow.org - Read the documentation
http://chat.metaflow.org - Chat with us
help@metaflow.org - Get help by email
Commands:
metaflow tutorials Browse and access metaflow tutorials.
metaflow configure Configure metaflow to access the cloud.
metaflow status Display the current working tree.
metaflow help Show all available commands to run.
$ metaflow tutorials pull
Metaflow (2.0.1)
Pulling episode "00-helloworld" into your current working directory.
Pulling episode "01-playlist" into your current working directory.
Pulling episode "02-statistics" into your current working directory.
Pulling episode "03-playlist-redux" into your current working directory.
Pulling episode "04-playlist-plus" into your current working directory.
Pulling episode "05-helloaws" into your current working directory.
Pulling episode "06-statistics-redux" into your current working directory.
Pulling episode "07-worldview" into your current working directory.
To know more about an episode, type:
metaflow tutorials info [EPISODE]
$ cd metaflow-tutorials/00-helloworldThat’s it. MetaFlow has a fancy CLI and no UI (to my knowledge). Compared to MLFlow, Metaflow has a more granular process control. For example, you can track and manage every single method in your Python code. They are so called steps in MetaFlow and they (python methods – metaflow steps) are controlled via Python decorators. The file „helloworld.py“ file contains a so called „Flow“ (Collection of „steps“ or python methods).
$ python3 helloworld.py show
Metaflow 2.0.1 executing HelloFlow for user:ubuntu
A flow where Metaflow prints 'Hi'.
Run this flow to validate that Metaflow is installed correctly.
Step start
This is the 'start' step. All flows must have a step named 'start' that
is the first step in the flow.
=> hello
Step hello
A step for metaflow to introduce itself.
=> end
Step end
This is the 'end' step. All flows must have an 'end' step, which is the
last step in the flow.
$ python3 helloworld.py run
Metaflow 2.0.1 executing HelloFlow for user:ubuntu
Validating your flow...
The graph looks good!
Running pylint...
Pylint not found, so extra checks are disabled.
Creating local datastore in current directory (/home/ubuntu/metaflow-tutorials/00-helloworld/.metaflow)
2020-01-30 14:50:52.288 Workflow starting (run-id 1580395852284119):
2020-01-30 14:50:52.291 [1580395852284119/start/1 (pid 18456)] Task is starting.
2020-01-30 14:50:52.660 [1580395852284119/start/1 (pid 18456)] HelloFlow is starting.
2020-01-30 14:50:52.691 [1580395852284119/start/1 (pid 18456)] Task finished successfully.
2020-01-30 14:50:52.695 [1580395852284119/hello/2 (pid 18462)] Task is starting.
2020-01-30 14:50:53.068 [1580395852284119/hello/2 (pid 18462)] Metaflow says: Hi!
2020-01-30 14:50:53.101 [1580395852284119/hello/2 (pid 18462)] Task finished successfully.
2020-01-30 14:50:53.105 [1580395852284119/end/3 (pid 18468)] Task is starting.
2020-01-30 14:50:53.478 [1580395852284119/end/3 (pid 18468)] HelloFlow is all done.
2020-01-30 14:50:53.511 [1580395852284119/end/3 (pid 18468)] Task finished successfully.
2020-01-30 14:50:53.512 Done!You see a pretty verbose logging over what step (method) is being executed. Every single Step like „start“, „hello“ and „end“ corresponds to a python method inside the „helloworld.py“ file.
Conclusion – MLFlow vs. Metaflow
Short version: go with MLFlow!
And here is why: Metaflow lacks an overview or a UI that will make this metadata, logging & tracking more accessible to us developers. Also the easy comparison between flows or models isn’t there. Metaflow seems to be highly intertwined with AWS (Sagemaker), which is great.
Compared to a framework that integrates also with Google Cloud, MS Azure, etc. – not so great. The concept of steps gives you a granular control over your Project. Also, you can define python dependencies on method level – meaning that every step could have it’s own versions of libraries – which is awesome.
The Framework MLFlow tops with the less intrusive structure – it doesn’t try gain control over your methods with decorators. It has a useful UI and integrations to many Cloud providers.

Andrey Bulezyuk is a Lead AI Engineer and Author of best-selling books such as „Algorithmic Trading“, „Django 3 for Beginners“, „#TwitterFiles“. Andrey Bulezyuk is giving speeches on, he is coaching Dev-Teams across Europe on topics like Frontend, Backend, Cloud and AI Development.



0 Comments